

Chaque semaine, des équipes passent des heures à réconcilier des chiffres qui auraient dû être identiques dès le départ. Pas parce que les données sont mauvaises. Elles sont là, dans l’entrepôt, à portée de requête. Mais parce que personne n’a posé les mêmes règles au même endroit. La semantic layer règle ce problème à la racine. En 2025-2026, elle est devenue l’infrastructure que les architectures data modernes attendaient et la condition sine qua non d’une IA analytique vraiment fiable.
Comprendre la couche sémantique
Définition & positionnement
Vous avez sans doute déjà vécu la scène. Une réunion de direction, deux responsables qui se regardent en chiens de faïence parce que leurs chiffres ne concordent pas. L’un affiche 3 800 clients actifs, l’autre 4 200. Même entreprise, même période, même outil. Ce n’est pas un problème de données corrompues, c’est un problème de sens. Chaque équipe a construit sa propre définition du mot « client », et personne ne le sait vraiment. C’est précisément là que la semantic layer entre en jeu.
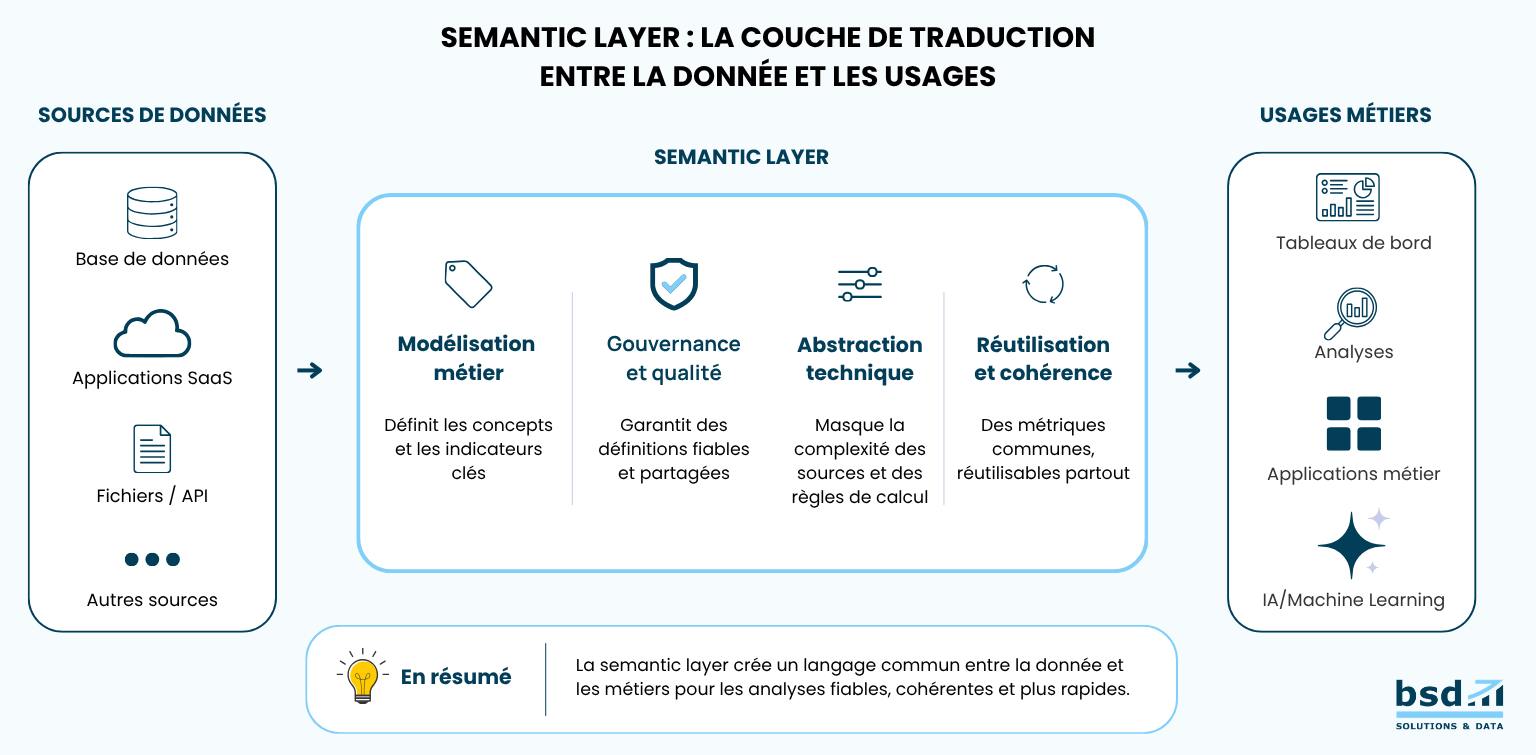
Une couche sémantique s’intercale entre vos systèmes de stockage (entrepôts de données, data lakehouses) et tous les outils qui les consomment, dashboards Power BI ou Tableau, requêtes analytiques, applications métier, agents IA. Elle ne stocke pas de données supplémentaires. Elle leur donne un sens partagé, compris de tous, qu’on soit ingénieur data ou directeur commercial.
Ce que la couche sémantique encode, ce sont les vérités analytiques de l’entreprise : définitions canoniques des métriques, relations logiques entre entités, filtres métier par défaut, politiques d’accès par profil. Ces vérités ne changent pas selon l’outil qui les interroge, elles sont définies une fois, centralisées, servies à la demande. Fini l’homonymie sémantique, ce phénomène où un même mot recouvre des réalités différentes selon l’équipe ou l’outil qui l’emploie.
Ce que la couche sémantique encode, ce sont ce qu’on appelle les vérités analytiques de l’entreprise : la définition canonique de chaque métrique (taux de conversion, panier moyen, churn mensuel), les relations logiques entre entités (un client peut avoir plusieurs commandes, une commande est liée à un produit), les filtres métier par défaut (exclure les comptes internes, ne considérer que les commandes confirmées), et les politiques d’accès différenciées selon les profils utilisateurs. Ces vérités ne changent pas selon l’outil qui les interroge. Elles sont définies une fois, centralisées, et servies à la demande à l’ensemble de l’écosystème analytique.
👉 En résumé
La couche sémantique, c’est le dictionnaire vivant de votre entreprise. Celui qui est directement branché sur vos outils, exécuté à chaque requête et qui garantit que tout le monde, humain ou machine, parle le même langage quand il s’agit de vos données.
Comment fonctionne une semantic layer ?
Pour comprendre où en est la couche sémantique aujourd’hui, il faut d’abord comprendre comment elle fonctionne et comment elle a évolué. Parce que derrière le terme générique se cachent des architectures très différentes, des philosophies d’implémentation qui divergent, et un marché d’outils qui s’est profondément reconfiguré ces trois dernières années.
Le fonctionnement en trois temps : définir, gouverner, exposer
Quelle que soit la solution retenue, une couche sémantique opère toujours selon la même séquence logique.
- Définir : Les équipes (data engineers, analytics engineers, parfois les métiers eux-mêmes) modélisent les concepts de l’entreprise : qu’est-ce qu’un « client actif » ? Comment calcule-t-on la marge brute ? Ces définitions sont formalisées dans un modèle sémantique, métriques, dimensions, relations entre entités, filtres par défaut. C’est un travail qui demande autant de rigueur que de collaboration entre équipes techniques et métier. Une définition posée sans les bonnes personnes dans la pièce, c’est une définition qui sera contestée six mois plus tard.
- Gouverner : La couche sémantique stocke les définitions et les protège. Elle détermine qui accède à quelle métrique, selon quel profil, avec quelle granularité. Un commercial voit son portefeuille, un directeur régional son agrégation, un CFO le consolidé groupe. Cette gestion fine des droits, Row-Level Security, Column-Level Security, s’intègre directement dans la couche sémantique, centralisée en un point unique plutôt que dispersée dans chaque outil de visualisation. Une règle définie une seule fois, appliquée partout.
- Exposer : La couche sémantique sert ses définitions aux outils consommateurs via des APIs standardisées (REST, GraphQL, SQL, XMLA selon les plateformes). Power BI, Tableau, Looker, un notebook Python, un agent IA : tous interrogent la même source de vérité, dans leur propre langage, avec la même logique métier partagée.
Les trois familles d’implémentation
Le marché s’est structuré autour de trois grandes approches. Chacune répond à des contextes organisationnels différents, avec ses propres compromis entre simplicité de déploiement, portabilité et indépendance vis-à-vis des éditeurs.
| Famille | Exemples | Points forts | Limite principale | |
| BI-native | Power BI Semantic Models, LookML (Looker), Tableau Semantics | Déploiement rapide pour les équipes déjà investies dans un outil ; définitions et consommation dans le même environnement | Définitions captives d’un seul outil ; risque de dérive si plusieurs outils coexistent | |
| Platform-native | Snowflake Semantic Views, Databricks Metric Views (Unity Catalog) | Gouvernance unifiée dans la plateforme de données ; métriques qui « voyagent » avec les données | Dépendance à un éditeur unique ; moins adapté aux architectures multi-cloud | |
| Universelle / Headless | Cube, AtScale, GoodData | Indépendante de tout outil de stockage ou de visualisation ; une définition servie via API à tous les consommateurs | Complexité d’intégration plus élevée ; nécessite une maturité data plus avancée | |
Le choix entre ces trois familles n’est pas une question de technologie, c’est une question de stratégie. Si votre organisation est Microsoft-first et que Power BI couvre 90 % de vos usages analytiques, les semantic models Fabric sont probablement le chemin le plus direct. Si vous gérez plusieurs outils de BI sur plusieurs plateformes cloud, une couche sémantique universelle vous évitera de maintenir des définitions en parallèle qui divergent inévitablement.
Gouvernance & sécurité
Qui peut voir quoi et comment le garantir ?
La gouvernance des données est un de ces sujets qu’on traite volontiers en dernier, après avoir déployé les outils, construit les pipelines, ouvert les accès. On s’en occupe quand un problème surgit : une fuite de données, un audit raté, un rapport confidentiel qui circule. La couche sémantique occupe ici une position stratégique que beaucoup d’organisations sous-exploitent, parce qu’elle est le passage obligé de toutes les requêtes, c’est l’endroit le plus logique pour faire vivre les règles d’accès.
Dans une architecture sans couche sémantique, ces règles sont définies à plusieurs endroits : dans l’entrepôt, dans chaque outil de BI, parfois dans les applications métier elles-mêmes. Quand un collaborateur change de poste ou qu’une réglementation évolue, il faut intervenir dans cinq endroits différents. Si l’un est oublié, la faille existe. La couche sémantique centralise ce point de contrôle, une mise à jour se propage instantanément à l’ensemble de l’écosystème.
Deux mécanismes complémentaires structurent cette gouvernance fine :
| Mécanisme | Ce qu’il contrôle | Exemple concret | Bénéfice principal | |
| Row-Level Security (RLS) | Les lignes de données accessibles selon le profil utilisateur | Un commercial Sud ne voit que son périmètre géographique ; même requête, résultats différents selon le profil | Pas de filtre manuel côté utilisateur ; règle centralisée, appliquée partout | |
| Column-Level Security (CLS) | Les colonnes ou champs exposés selon le profil utilisateur | Les salaires, marges client ou données RGPD masqués pour les profils non autorisés ; valeurs anonymisées en remplacement | Protection des données sensibles sans intervention dans chaque outil consommateur | |
RGPD, data stewardship et conformité réglementaire
Le RGPD impose de savoir où se trouvent les données personnelles, qui y accède, comment elles sont utilisées et combien de temps elles sont conservées. La couche sémantique répond à ces exigences de façon native : cartographie lisible des accès, politiques de masquage intégrées directement dans les définitions sémantiques, versioning des règles pour une traçabilité auditale. Le data stewardship y trouve aussi un support concret. Chaque métrique associée à un propriétaire identifié, une définition documentée, une date de dernière validation, consultable par tous les consommateurs sans passer par un wiki que personne ne lit.
Quand une entreprise revoit sa politique de reconnaissance du chiffre d’affaires ou intègre une nouvelle filiale, la mise à jour se fait en un seul endroit et se propage automatiquement. Le versioning des définitions permet de répondre en quelques secondes à des questions comme : « Le taux de rétention affiché dans ce rapport de 2023 était-il calculé selon la même définition qu’aujourd’hui ? » Les contrôles qualité automatisés, tests unitaires sur les métriques, alertes sur valeurs aberrantes, validation à chaque déploiement, détectent les erreurs avant qu’elles atteignent les utilisateurs finaux.
Couche sémantique & Intelligence Artificielle
Ce qui se passe quand un LLM interroge vos données sans contexte
Connecter un LLM directement à votre entrepôt de données, c’est lui demander de deviner seul ce que signifient amt, amt_net_usd ou status_cd dans votre contexte métier. Il produit une réponse plausible, ce qui, sur des données financières ou opérationnelles, est souvent plus dangereux qu’une absence de réponse. Le LLM retourne un chiffre proprement formaté, accompagné d’une explication convaincante. L’utilisateur le copie dans sa présentation, prend une décision. Ce n’est que bien plus tard qu’on découvre que le « chiffre d’affaires T3 » incluait les remboursements.
La couche sémantique est le briefing que le LLM n’a jamais reçu. Elle encode le savoir implicite de vos analystes, ces conventions non documentées, ces exclusions historiques, ces règles qui se transmettent de bouche à oreille dans une structure que l’IA lit et respecte à chaque requête.
Microsoft, Databricks et Snowflake ont tous traduit ce constat en choix d’architecture. Dans chaque cas, la logique est identique : l’agent IA travaille à partir de définitions certifiées et ne peut pas en sortir. C’est précisément cette contrainte qui le rend fiable.
| Plateforme | Implémentation | Agent IA | Particularité | |
|---|---|---|---|---|
| Microsoft Fabric / Power BI | Semantic Models + Ontologie Fabric IQ | Copilot, Data Agents | « Prep for AI » : définit explicitement les métriques et tables accessibles à l’IA | |
| Databricks | Metric Views (Unity Catalog, YAML) | AI/BI Genie | Métadonnées sémantiques attachées à chaque métrique depuis oct. 2025 | |
| Snowflake | Semantic Views | Cortex Analyst | Précision SQL supérieure à 90 % sur cas réels | |
| Tableau / Salesforce | Tableau Semantics | Tableau AI Assistants | Définitions centralisées connectées au Data Cloud | |
| Palantir | Ontology (Foundry) | AIP Agents | Couvre logique analytique et opérationnelle | |
Comment mettre en place une semantic layer ?
Par où commencer concrètement ?
La question qui revient systématiquement : par où attaquer ? La réponse tient en une ligne, commencez par cinq métriques, pas par l’ensemble du patrimoine data.
Listez les indicateurs sur lesquels vos équipes ne sont jamais d’accord : chiffre d’affaires, taux de conversion, clients actifs, churn mensuel, panier moyen. Pour chacun, documentez précisément la formule de calcul, les filtres appliqués, les tables sources impliquées et le propriétaire métier. Cet exercice prend une demi-journée. Il révèle généralement cinq à dix définitions concurrentes là où tout le monde croyait qu’il n’y en avait qu’une.
Le choix de l’outil vient ensuite. Il découle directement de votre contexte : une organisation Microsoft-first avec Power BI dominant ira vers les semantic models Fabric, enrichis via « Prep for AI » pour les usages Copilot. Une organisation multi-outils sur plusieurs plateformes cloud regardera du côté des solutions universelles comme Cube ou AtScale. Le tableau comparatif présenté plus haut dans cet article vous donnera les repères nécessaires.
Deux principes font la différence entre un déploiement qui tient dans le temps et un projet qui reste dans les tiroirs :
- Le premier : impliquer les métiers dès la phase de définition, pas en validation finale. Une métrique définie sans les bonnes personnes dans la pièce sera contestée six mois plus tard.
- Le second : traiter les définitions comme du code, versioning Git, revue par les pairs, tests automatisés avant déploiement. Modifier la définition du « churn mensuel » doit laisser une trace, notifier les consommateurs, et être validé par le propriétaire métier. Cette discipline, appliquée dès le début, évite la dette sémantique qui s’accumule silencieusement.
La couche sémantique n’est pas un projet technique de plus à confier à votre équipe data engineering. C’est une décision stratégique qui touche à la façon dont votre organisation produit, partage et exploite ses données aujourd’hui dans vos tableaux de bord, demain dans vos agents IA.
BSD accompagne ses clients dans cette transformation. De l’audit de l’existant à l’implémentation opérationnelle, en passant par le choix de l’architecture adaptée à votre contexte. Que vous soyez dans un environnement Microsoft-first avec Power BI et Microsoft Fabric, ou dans une architecture multi-cloud qui nécessite une couche sémantique universelle, nos équipes vous aident à poser les bonnes fondations dès le départ.
FAQ : Semantic layer, les questions les plus fréquentes
aucun
Qu’est-ce qu’une semantic layer ?
Une semantic layer est une couche logique positionnée entre vos systèmes de stockage et vos outils analytiques. Elle encode les définitions canoniques de vos métriques, les relations entre entités et les règles d’accès par profil. Résultat : toutes les équipes, humains et agents IA, interrogent la même source de vérité.
Quelle est la différence entre une couche sémantique et un modèle de données classique ?
Un modèle de données structure les données physiquement. La semantic layer y ajoute une dimension métier : définitions des métriques, filtres par défaut, politiques d’accès et relations logiques entre entités. Elle est exposée via API à tous les outils consommateurs, indépendamment de leur nature.
Comment choisir entre une semantic layer BI-native, platform-native ou universelle ?
Le choix dépend de votre contexte : une organisation Microsoft-first avec Power BI dominant ira vers les semantic models Fabric. Une architecture multi-outils sur plusieurs clouds nécessitera une couche universelle comme Cube ou AtScale. La question n’est pas technique, c’est une décision de stratégie data.
Par où commencer pour déployer une semantic layer ?
Commencez par cinq métriques sur lesquelles vos équipes ne s’accordent jamais : chiffre d’affaires, taux de conversion, churn, etc. Documentez formule, filtres, sources et propriétaire métier pour chacune. Cet exercice révèle les définitions concurrentes existantes et pose les bases d’un déploiement structuré.
Échangez avec notre équipe et bénéficiez d’un accompagnement

Alexis Bourdeau
Directeur de projet


