
Le Big Data n’est plus un buzzword réservé aux géants du web. Vos applications, vos outils métiers, vos emails, vos échanges Teams, vos capteurs IoT… tout ce que votre organisation fait au quotidien génère une masse de données colossale. La vraie question n’est plus « avons-nous des données ? » mais plutôt « que faisons-nous vraiment de cette richesse ? ». Bien exploité, le Big Data permet d’accélérer vos décisions, d’anticiper les risques et de créer de nouveaux services. Mal maîtrisé, il devient un coût et une source de complexité. À vous de choisir de quel côté vous voulez vous situer.
Comprendre le Big Data
Lorsque l’on parle de Big Data, on parle bien plus que d’un grand volume de fichiers accumulés dans un système informatique. Le Big Data désigne un ensemble massif, continu et hétérogène de données que les outils traditionnels ne parviennent plus à stocker, analyser ou interpréter efficacement. C’est un phénomène qui dépasse la simple dimension technique : il transforme la manière dont les entreprises observent leur environnement, anticipent, décident et créent de la valeur.
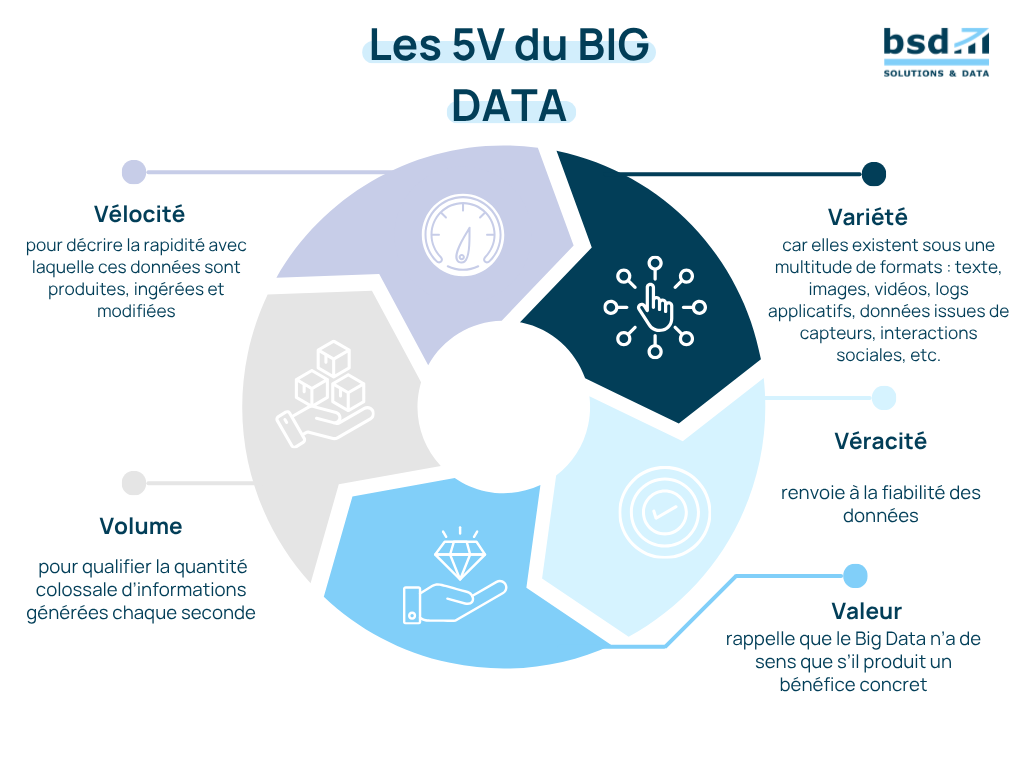
Ce concept repose historiquement sur les 3V :
- Volume, pour qualifier la quantité colossale d’informations générées chaque seconde ;
- Vélocité, pour décrire la rapidité avec laquelle ces données sont produites, ingérées et modifiées ;
- Variété, car elles existent sous une multitude de formats : texte, images, vidéos, logs applicatifs, données issues de capteurs, interactions sociales, etc.
Au fil du temps, deux autres dimensions se sont imposées : la Véracité, qui renvoie à la fiabilité des données, et la Valeur, qui rappelle que le Big Data n’a de sens que s’il produit un bénéfice concret.
👉 Le saviez-vous ?
En France, le volume de données générées par les entreprises et les particuliers a été multiplié par plus de 20 en une décennie. L’enjeu n’est plus de capter toujours plus d’information, mais de réussir à la transformer en avantage compétitif. Source : L’Usine Digitale
Cette croissance fulgurante est intimement liée à l’évolution de nos usages. Chaque action numérique : un achat en ligne, un passage en caisse, un trajet géolocalisé, une interaction sur un réseau social, une donnée issue d’un capteur IoT, produit un signal exploitable. Les entreprises ne gèrent plus seulement leurs systèmes internes : elles naviguent désormais au cœur d’un écosystème global et interconnecté où tout génère de la donnée.
Ces informations peuvent être :
- structurées, comme les données CRM ou financières ;
- semi-structurées, comme les logs de navigation ou les fichiers JSON ;
- non structurées, comme des photos, des vidéos, des documents métiers ou des échanges écrits.
Cette diversité impose des technologies capables de stocker, traiter et interpréter ces données à grande échelle. Les modalités d’ingestion, les formats, les vitesses de traitement et les besoins métiers exigent des infrastructures modernes, un sujet que nous explorerons dans les sections suivantes.
Origine, évolution et dynamiques du Big Data
Pour bien asseoir votre stratégie, il est essentiel de retracer l’historique du phénomène Big Data, de celui qui était à la marge à celui qui oriente désormais la transformation digitale. Voici comment ce concept a émergé, évolué, puis s’est révélé comme moteur de l’économie data-driven.
1. Aux sources du Big Data
L’expression « Big Data » apparaît dans la bibliothèque numérique de l’Association for Computing Machinery (ACM) dès octobre 1997 : un premier signal que la gestion de « grands ensembles de données » devenait un enjeu technologique à part entière. (RiskInsight)
Dans les années 1990, ce sont surtout les secteurs scientifiques, universitaires et techniques (physique, biologie, astrophysique) qui manipulaient des volumes importants : les outils classiques montraient vite leurs limites, ce qui a nourri l’émergence du terme.
2. Passage à l’échelle et explosion des usages
Au début des années 2000, le basculement s’opère : l’hyper-connectivité, l’essor des smartphones, la prolifération des capteurs et de l’internet des objets (IoT) produisent des flux de données qui ne cessent de croître en volume et en vitesse. Ce qui était une curiosité académique devient un défi industriel.
Parallèlement, les architectures informatiques évoluent : le stockage distribué, le traitement massif, les clusters, les solutions cloud commencent à rendre possibles ce qui était auparavant ardu ou imposeux.
👉 Bon à savoir !
En France, selon l’INSEE, en 2018, 37 % des sociétés de 250 personnes ou plus ont réalisé des analyses de données massives, contre 33 % dans l’UE, ce qui montre l’ancrage de ce phénomène dans le tissu économique français.
3. Le Big Data comme levier de transformation digitale
Aujourd’hui, le Big Data n’est plus un simple outil parmi d’autres : il s’impose comme une matière première stratégique pour les entreprises qui veulent évoluer vers des organisations intelligentes.
Le Big Data permet aux entreprises de passer à un modèle data-driven, où la donnée nourrit non seulement des rapports mais aussi des automatisations, des prédictions et de l’intelligence embarquée, ce qui redéfinit les processus métiers, les modèles d’organisation et les priorités IT.
4. L’intégration croissante avec l’IA et les modèles prédictifs
Cette dynamique n’aurait pas la même intensité sans le couple puissant : Big Data + Intelligence Artificielle. Plus qu’un simple épiphénomène, l’IA transforme la donnée en insight, les algorithmes transforment les océans de données en valeur.
Les architectures modernes englobent désormais l’apprentissage automatique (Machine Learning), le deep learning, et des mécanismes d’optimisation continue (MLOps) capables d’agir en quasi-temps réel.
Les organisations qui réussissent ce tournant intègrent le Big Data dès la phase de conception des outils, la donnée devient native et stratégique.
5. Une dynamique en constante accélération
Enfin, gardez à l’esprit que cette dynamique reste extrêmement fluide. Le Big Data ne se stabilise pas : il change de nature, se combine à d’autres ruptures (Edge computing, Data Mesh, IA générative, métavers, objets connectés) et pousse les entreprises à revoir régulièrement leurs architectures, leurs compétences et leurs usages.
Les sources, technologies et architectures du Big Data
Les principales sources de données massives
Pour exploiter pleinement le Big Data, il est indispensable de comprendre d’où proviennent les données qui alimentent vos analyses. Elles naissent d’abord des objets connectés et des capteurs industriels, qui génèrent en continu des informations sur l’état des machines, les conditions environnementales ou les mouvements logistiques. Elles émergent aussi des usages numériques : chaque navigation web, chaque interaction sur une application mobile, chaque action sur une interface produit un signal exploitable, précieux pour analyser les comportements et optimiser l’expérience utilisateur, à condition de respecter le RGPD et la confidentialité.
Les réseaux sociaux constituent une autre source majeure : ils reflètent des opinions, des tendances, des préférences, mais nécessitent une expertise avancée pour analyser texte, images ou vidéos sans reproduire de biais. Les données plus classiques issues des systèmes métiers : CRM, ERP, facturation, supply chain deviennent elles aussi stratégiques lorsqu’elles sont consolidées dans un environnement Big Data, car elles offrent une vision transverse des opérations, des coûts ou des performances.
Enfin, les données multimédia (images, audio, vidéos, géolocalisation) connaissent une croissance spectaculaire avec la généralisation des caméras, des drones ou des capteurs satellitaires. Leur exploitation requiert des technologies plus puissantes, notamment l’IA et le Deep Learning, mais elles offrent un avantage décisif aux organisations capables de les analyser.
Architectures modernes pour exploiter le Big Data
Exploiter réellement le Big Data ne consiste pas à accumuler des données dans un entrepôt numérique. Cela exige une architecture robuste, évolutive et cohérente, capable d’absorber la croissance, de garantir la qualité et d’alimenter efficacement les usages métiers et IA. Les entreprises les plus avancées ont bien compris que l’architecture n’est plus un choix technique : c’est un levier stratégique.
➡️Data Lakes : centraliser et libérer la donnée
Le data lake est devenu la pierre angulaire des environnements Big Data. Il permet de stocker les données sous leur forme brute, sans contrainte de structure, et d’absorber des volumes massifs et hétérogènes. Cette approche donne aux métiers une véritable liberté d’exploration et favorise l’expérimentation.
➡️Pipelines ETL / ELT : fiabiliser et préparer les données
Aucune architecture Big Data ne fonctionne durablement sans pipelines solides. Les processus ETL ou ELT orchestrent l’ingestion, la transformation et la mise en qualité des données.
Pour être réellement efficaces, ces flux doivent être résilients, automatisés et monitorés. La CNIL rappelle d’ailleurs que les mécanismes de conformité doivent être intégrés dès la conception, notamment lorsqu’il s’agit de données sensibles.
➡️Architectures distribuées : performance et résilience
Les traitements Big Data reposent sur des architectures distribuées, capables de répartir les calculs sur plusieurs nœuds. Résultat : davantage de performance, une meilleure disponibilité et une montée en charge fluide — des bénéfices impossibles à atteindre avec un serveur unique.
➡️Approche DataOps : industrialiser les flux de données
Gérer la donnée “à la main” n’est plus envisageable. L’approche DataOps vise à automatiser les contrôles qualité, les déploiements, le versioning, les tests et l’orchestration.
Elle rapproche les équipes data, IT et métiers, tout en garantissant des pipelines fiables, reproductibles et mieux gouvernés.
➡️MLOps : intégrer et maintenir les modèles d’IA
Enfin, une architecture Big Data moderne doit pouvoir alimenter des modèles d’IA, les entraîner, les déployer puis les superviser dans le temps. Le MLOps apporte aux projets de Machine Learning les pratiques d’industrialisation du DevOps : automatisation, supervision continue, traçabilité et qualité.
Les usages, bénéfices et enjeux du Big Data
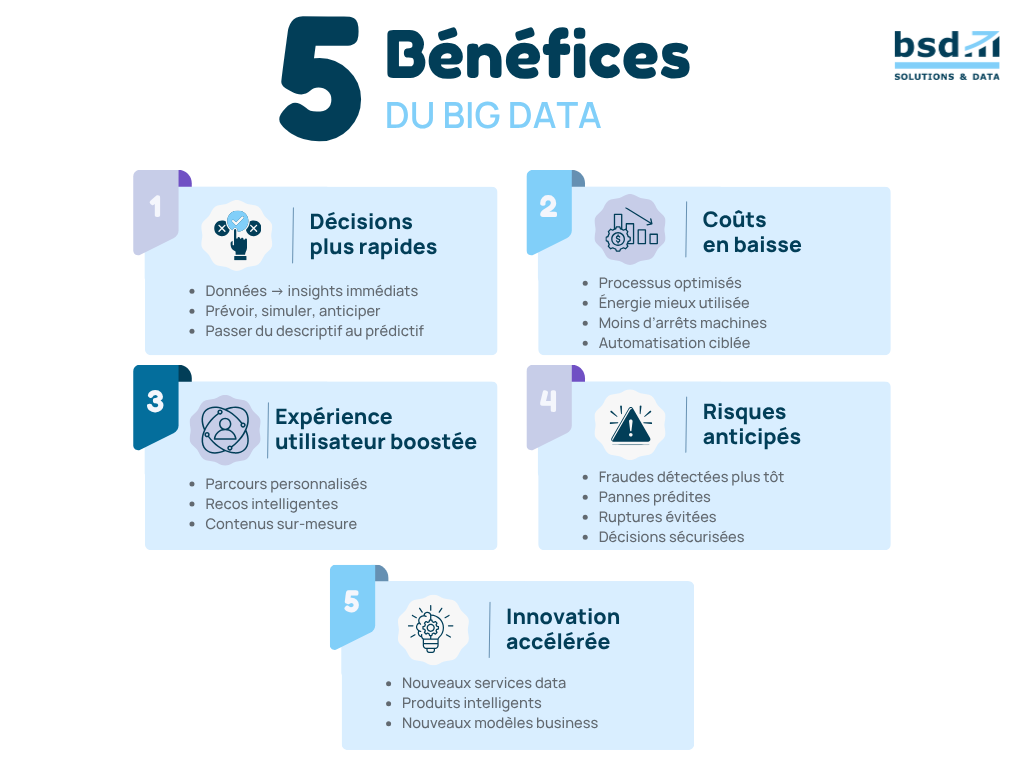
Bénéfices stratégiques pour les organisations
Adopter une stratégie Big Data ne relève plus de l’expérimentation : c’est une démarche structurante qui influence la performance, l’innovation et la compétitivité de toute organisation. Pour vous, dirigeants et responsables IT, voici les bénéfices concrets et stratégiques que le Big Data débloque lorsqu’il est intégré de manière cohérente dans vos processus métiers.
Enjeux, limites et défis du Big Data
Si le Big Data ouvre des perspectives considérables, il comporte aussi des défis majeurs. Pour en tirer pleinement parti, les organisations doivent affronter des enjeux techniques, réglementaires et humains qui conditionnent la fiabilité et la valeur des analyses. Ces défis sont souvent sous-estimés, alors qu’ils sont déterminants pour la réussite d’une stratégie data.
Gouvernance incontournable : qualité, traçabilité, sécurité
Aucune initiative Big Data ne peut prospérer sans un cadre de gouvernance solide : dictionnaire de données, référentiels, règles de qualité, responsabilités, droits d’accès.
👉 Remarque
La CNIL rappelle que la gouvernance est indispensable pour assurer la conformité, l’intégrité et la sécurité de la donnée : « La gouvernance de la donnée implique la maîtrise du cycle de vie et la documentation des traitements pour garantir leur fiabilité. »
Gestion du biais dans les données et dans les modèles
Les données massives ne sont pas neutres : elles reflètent des comportements, des systèmes, parfois des inégalités. Si elles sont incomplètes, déséquilibrées ou mal préparées, les modèles analytiques ou IA peuvent produire des résultats faussés.
Ce défi impose une vigilance constante : contrôle des jeux de données, revue des modèles, supervision continue.
Respect strict du RGPD, confidentialité et gestion des accès
Le Big Data manipule souvent des données sensibles ou personnelles (trajectoires de navigation, transactions, géolocalisation, historique de service).
Le RGPD exige que chaque entreprise justifie la finalité du traitement, limite les accès, sécurise les flux et documente chaque opération.
Complexité technique nécessitant des compétences spécialisées
Le Big Data mobilise un écosystème technologique dense : stockage distribué, ingestion, NoSQL, streaming, IA, DataOps, MLOps… Cette complexité exige des profils spécialisés (data engineers, data architects, analysts, experts cloud).
Échangez avec notre équipe et bénéficiez d’un accompagnement

Alexis Bourdeau
Directeur de projet


